|
|
|
|
|
|
|
|

Oct 22, 1997Implementing Mixed
Hardware/Software Rendering in Direct3D*
Haim Barad, Mark Atkins, Herb Marselas
| Information in this document is provided in
connection with Intel products. No license, express or
implied, by estoppel or otherwise, to any intellectual
property rights is granted by this document. Except as
provided in Intel's Terms and Conditions of Sale for such
products, Intel assumes no liability whatsoever, and
Intel disclaims any express or implied warranty, relating
to sale and/or use of Intel products including liability
or warranties relating to fitness for a particular
purpose, merchantability, or infringement of any patent,
copyright or other intellectual property right. Intel
products are not intended for use in medical, life
saving, or life sustaining applications. Intel may make
changes to specifications and product descriptions at any
time, without notice. Copyright (c) Intel Corporation 1997. *Third-party brands and names are the property of their respective owners. |
The growing popularity of PC 3D hardware has sparked debate among software developers, whether to continue developing software rendering engines or to completely abandon them in favor of hardware. Both choices offer advantages and disadvantages. Luckily there is a way to get the best of both worlds: combine, or mix, the two rendering methods. By using Mixed Rendering, gamers and programmers get the flexibility and quicker evolution of software and the speed of dedicated 3D hardware. This happy medium can exist within the standard graphics APIs for Microsoft Windows*: DirectDraw* and Direct3D*. Several methods exist for mixing software and hardware rendering--color keying, overlays, alpha BLT, Z-buffered BLT, or animated texturing. We have implemented samples using Direct3D on several hardware accelerators. Performance issues arise in synchronizing hardware and software, but these problems are solvable to the point of zero-cost for adding software pixels to hardware scenes. We have success implementations on Pentium� and Pentium� II processors, with graphics hardware including ATI Rage Pro* 3D, 3Dfx Voodoo* Graphics, Rendition Verite* V1000, and Matrox Mystique*.
Game developers want to differentiate their titles as much as possible, in visual quality, speed, and complexity. Prolific 3D accelerators in the mainstream market raise potential 3D quality and performance, while leveling visual complexity. Developers can now freely exploit hardware acceleration, but lose fine-tuned control of the visual quality when hardware (via an API) performs the rendering. The API for most Windows game developers, Microsoft's Direct3D, provides hardware-independence but can limit uniqueness of the game's look.
For example, developers want the
great features of a customized 3D software engine, and want to
push the limits of quality and visual complexity with techniques
commonly used in offline rendering engines (e.g. procedural
textures, curved surfaces, ray tracing). However, they still want
Direct3D and its Hardware Abstraction Layer (HAL) to render the
scene as quickly as possible on widely-installed 3D hardware.
Further, the speed and capabilities of 3D hardware and CPUs will
increase significantly for the foreseeable future. But you won't
see clever new techniques in "fixed function" 3D
hardware accelerators until years after they have been
implemented in software, if ever.
We illustrate the concept of mixed rendering using the familiar Direct3D sample application, "Tunnel." In our case, the tunnel is our background over which we send some object traveling. For simplicity, we use a procedurally-textured 400-triangle torus (i.e. a marble bagel?) for the software-drawn object.
Marble Bagels Traveling in the Tunnel is not a clever game, but it does illustrate the required infrastructure of mixed rendering and provides an example of an advanced technique unavailable in any 3D accelerator. But your app need not use procedural textures… pick any special rendering technique you like and apply it.
The tunnel has a low number of
large polygons (our background), while the bagel is an object
with a larger number of small polygons (complex foreground
object). Figure 1 shows a sample screen from the application.
Figure 1 - Scene from Marble Bagels Traveling Through the Tunnel
Our first mixed rendering application made concurrent use of both the Direct3D Hardware Abstraction Layer (HAL) and Hardware Emulation Layer (HEL). We combined the Direct3D Twist and Tunnel applications, with Twist in software and Tunnel in hardware. This example could be rendered entirely with hardware, but using mixed rendering shows the methodology and allows comparisons of performance. While we don't advocate mixed rendering for modes that are widely available in 3D accelerators, we use this example to illustrate the concurrency available in some 3D hardware.
Performance depends on the 3D hardware, since different accelerators and their drivers allow for different amounts of concurrency. That is, better hardware accelerators permit the CPU to continue calculating while the hardware draws, while lower-end hardware tends to require the CPU to idle, waiting for hardware completion. Performance also depends upon the rasterization load balancing for the software and hardware. This application's performance using the multithreaded methodology described later appears in Table 1.
Hardware Only |
Mixed Rendering |
|
Configuration A |
21 fps |
25 fps |
Configuration B |
28 fps |
27 fps |
Table 1.
Performance Results for Two Configurations (Gouraud shaded,
texture mapped)
Config A: Pentium�
processor with MMXTM Technology, 150MHz, Matrox
Mystique*, point sampled textures. Config B: Pentium� II
processor, 233 MHz, with Creative Labs 3DBlaster* PCI, with
bilinear filtering
The performance in this example is not an apples to apples comparison, as the 3DBlaster supports bilinear filtering while the Mystique does not, and the different CPUs complicate comparisons. So comparison should only be made between the Hardware Only and the Mixed Rendering columns for each configuration.
The results in Table 1 show that the performance of configuration "A" improved when we mixed software and hardware rendering, while the performance of configuration "B" degraded a bit. This improvement can be traced to two key factors: threading and hardware concurrency.
Originally our rendering process contained a single thread, which fed triangles to the 3D accelerator card as fast as possible. If an accelerator card is fast, the thread runs at the CPU's maximum rate. Unfortunately, there are situations and cards which process data slowly, and times when data needs to be blocked entirely. If the card's command memory too full to accept more triangles, or if it needs to wait for the vertical blank interval (VBI) to flip the drawing surfaces, the thread has to block (wait).
By adding a second thread, the rendering process has the opportunity to do something useful if the original hardware rendering thread blocks. In this case that second thread is software-only rendering. This concurrency between the CPU and the accelerator accounts for the performance increase in the 3DBlaster -- we had two rendering engines at work simultaneously, resulting in a performance gain in spite of the overhead required to composite the two images in the end. The Mystique (at least with the early-1997 driver we tested) did not support concurrency (nor bilinear filtering), resulting in a small performance loss, but future 3D hardware and drivers should do better.
The motivation for mixed rendering is not performance. The ability to integrate special features and advanced techniques not supported in 3D hardware is the overriding benefit.
Mixed rendering should be multithreaded to exploit concurrency and must manage the priorities of the two threads during different stages of the rendering process. Figures 2a and 2b illustrate software methodologies for multithreaded Mixed Rendering without deadlock: one case using a separate BLT composite and a single buffer in the software thread, and another case using texture mapping composite and a double buffer in the software thread. Both scenarios assume a complex flipping surface (i.e. backbuffer and frontbuffer) for the HW thread.
In Figure 2a, the HW thread handles the drawing of the parts of the scene with 3D hardware, as well as the composite/flip operations. Software rendering is done in a separate thread to an offscreen buffer in system memory in a loop using synchronization events. Two distinct synchronization events (SWReady and CompositeDone) are used to avoid deadlock in case the rasterization load becomes unbalanced (i.e. much heavier in one thread than the other).
The SWReady event is set when the software thread has finished its frame and its results are ready for compositing (using a BLT operation) with the frame generated in the main thread. The software thread must wait for the results of this rendering to be consumed by the main HW thread (via BLT composite), signaled by the event CompositeDone. Once the composite has completed, the software thread can begin working on the next frame.
Using multiple buffers (Figure 2b) on the software thread can allow progress to continue into the next frame(s) without waiting for the results to be consumed from the current buffer. We call the buffers in the SW thread "Active Cache" and "Developing Cache," names whose meaning will become clear later as we discuss integrating "image caching" (see section on MR2). We have made a tradeoff of memory allocation (extra buffers) for increased performance.
The SW thread
always draws into the developing cache. The HW thread must wait
for the SW thread to get one frame ahead of the HW, in order to
provide a texture ready for compositing into the HW scene. For
each frame, the active cache is copied into the HW's video
memory. Then the hardware draws the entire scene
("DrawHW*") which includes the texture map composite
onto a single polygon in the HW scene. We'll discuss this
compositing method more later.
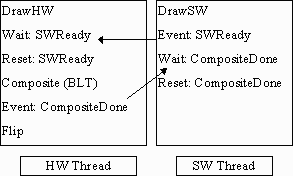
Figure 2a. BLT composite and single buffer in SW thread
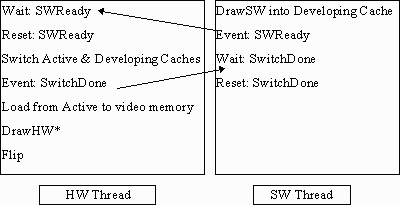
Figure 2b. Texture mapping composite and double buffer in SW thread
Many methods exist for combining the results of the hardware and software threads. DirectDraw provides several options for the BLT operation:
Currently, the "BLT with
Z-buffer" is not enabled in DirectDraw, but will hopefully
be in future versions. Z-buffer information is required when mixing interpenetrating
objects as shown in Figure 3. However, distinct objects
(even those are partly occluded) can be handled using the other
methods.
Figure 3. Interpenetrating objects
In spite of the fact that BLT with Z is not currently enabled in DirectDraw, we can composite distinct (as opposed to interpenetrating) objects in the scene based on their Z values.
The results of the software rendering are texture mapped (transparently) onto a rectangle in the hardware backbuffer. We call this Single POlygon Textures (SPOTs), which also take advantage of the 3D hardware's capability for filtered texture mapping. It also allows the software to tune performance by rendering at a smaller size, later stretched by HW, or to get special effects like distortion. Figure 4 is an example of a mostly HW accelerated background with a high quality, albeit small, SW rendered object. The HW will texture map the motorcycle to the SPOT during the drawing of the HW scene. The SW object (i.e. the motorcycle) can interact with the HW scene (such as go behind trees or obscure other HW objects), if we move the SPOT via the HW thread to the proper place in the scene and transparently texture map to the SPOT.
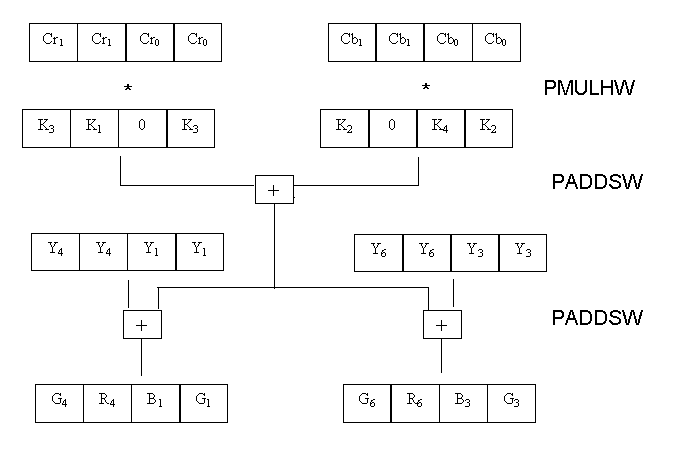
Figure 4. Composite via texture map to SPOT
Compositing via texture mapping also offers a performance advantage. Many 3D cards perform better if no 2D operations (e.g. BLT) get interspersed with 3D rendering. BLT operations on HW with otherwise good concurrency will cost performance, as the 2D request typically causes the HW to "flush" or "drain" its deeply pipelined 3D operations before initiating the 2D.
Another note: some hardware will even support differing pixel depths for the source and destination of the BLT or texture mapping. Also note that with the higher bandwidths of AGP (Accelerated Graphics Port) hardware, texturing out of system memory will be faster, and it will not require explicit copying of the texture to "local" video memory. However, software may want to render each frame into a system memory surface, then copy it to AGP memory explicitly for performance reasons related to locking overhead.
The CPU can best render objects that exploit specialized or advanced 3D techniques. Often these are interesting foreground objects. Such objects are usually composed of smaller triangles, and software rasterization performance on small triangles is more competitive with hardware. In other words, the CPU is faster at triangle throughput than at pixel fill, and creating the commands and data for hardware requires a lot of time compared to the time to draw small triangles. This strategy corresponds roughly to background/foreground object partitioning.
Again, mixed-mode rasterization should not be used for performance reasons alone. Until the infrastructure for exploiting concurrency is enhanced, there may be no appreciable performance gain (and possibly a loss).
The application "Marble Bagels Through the Tunnel" demonstrates a texturing technique not supported by 3D HW, namely procedural textures. It uses a Perlin Noise generator and turbulence (optimized for MMX™ technology) to produce the marble-like appearance. A discussion of procedural textures can be found on Intel's Developer Website.
The first code snippet in the appendix creates a separate thread for the SW rendering and also the necessary synchronization events. We won't discuss the details here. [Andre LaMothe provides an excellent tutorial on multithreading in the July 1997 issue of Game Developer Magazine, http://www.gdmag.com/]
The next two code snippets in the appendix illustrate the basic methodology. The first routine, DrawFrame is run in the hardware/Main thread. The hardware scene is rendered separately and uses the call WaitForSingleObject to synchronize with the software thread. The hardware thread is then suspended until the software thread sends this event. Once the event is received, the hardware thread can continue on to the composite (in this case a BLT is used) and then flip. Also, once the hardware thread has consumed the results of the software rendering, it sends an event using SetEvent to let the software thread know it can continue to the next frame.
The second routine DrawFrameSW is run in the software thread. It interacts with the hardware thread using WaitForSingleObject and SetEvent to synchronize the activities.
Running two separate threads is the first step towards extra performance. Like most multithreaded operating systems, the Windows thread scheduler dynamically changes thread priorities. Higher priority threads run more often, and those with lower priorities run less often. A thread waiting for an I/O operation to complete will have it's priority decreased. Since I/O operations typically take hundreds or thousands of CPU cycles, there's no reason to waste time checking on a thread that isn't ready to continue. However, when the scheduler determines that the thread has completed an I/O operation, it's priority will be increased. This gives the thread a chance to process the result of the I/O.
Dedicating one thread to software rendering and another to hardware rendering leverages the behavior of the thread scheduler. The hardware rendering thread performs several I/O intensive operations -- sending triangles to the hardware rasterizer, compositing the software rendered objects, and flipping the drawing surfaces. The scheduler decreases the priority of the thread as each I/O event occurs, and then raises the priority when it completes. Even though both the hardware and software rendering threads begin at the same priority, decreasing the hardware thread priority allows the software thread to run more often. This extra CPU time for the software allows it to complete more rendering while the other thread waits for I/O.
Running separate threads for hardware and software rasterization is one form of concurrent operation.. There is also a second level of concurrency taking place, between the hardware rasterization thread and the 3D hardware accelerator.
Ignoring other threads in the system, the scheduler switches between executing the software and hardware rendering threads. The hardware accelerator essentially provides a third thread of processing. Most of the activity of this thread takes place on the hardware accelerator itself, giving true parallel operation with the CPU.
 Figure 5. Progress of both
threads
Figure 5. Progress of both
threads
Figure 5 demonstrates how the scheduler switches between the software and hardware rendering threads. At time T4, the hardware rendering thread submits triangles to the 3D accelerator. This causes the thread to block at T5, pending the completion of triangle processing. The software rendering on the CPU and the triangle rasterization on the accelerator run in true parallel execution.
Note the potentially long time periods when either the CPU or the 3D accelerator aren't performing any useful operations. This is due either to idling or stalling. The 3D accelerator sits idle, waiting for something to process from T1 until T4. The CPU is stalled at T9 and T11 waiting for the BLT and flip operations to complete before continuing.
By slightly recoding, stalls and
idles can be reduced and the entire operation can take less time
(figure 6).
 Figure 6: Improved Concurrency Mixed
Rendering
Figure 6: Improved Concurrency Mixed
Rendering
The first modification is to control the number of triangles submitted to the 3D accelerator. For any API or driver, there is an overhead associated with processing data. In the case of Direct3D versions 3 & 5, approximately 100 vertices worth of triangles is the minimum to submit to achieve best performance. This performance is constant, regardless of whether the ExecuteBuffer or DrawIndexedPrimitive function is used. Any less than that, and it will still take about the same amount of time to complete and return, due to overhead.
On the other hand, thousands of vertices shouldn't be submitted at once either. Submitting vertices for rasterization should be arranged in such a way as to not idle, or stall, the CPU or the 3D accelerator for long periods of time. Breaking a large number of vertices into multiple submissions, T4 and T8, allows better throughput and parallel execution.
The second modification is to remove stalls in the hardware rendering thread. The two biggest culprits: waiting for the BLT and the flip operations to complete. By running these asynchronously, the hardware thread no longer needs to block for a long period. The 3D accelerator can also queue and perform the operations in parallel with the beginning of the next frame.
Figures 7a, 7b, & 7c show the effects of concurrency and compositing method on several platforms. These graphs do not fairly compare platforms with each other; they only illustrate the concurrency available and compositing on platforms of various computational power.
Figure 7a shows a substantial performance degradation when adding the SW rendering portion to the regular "Tunnel" application. This is due partly to the large computational load on the SW thread generating the procedural textures. However, our measurements also show that this platform did not exhibit as much concurrency as the next two platforms.
The next two cases (Figures 7b & 7c) not only illustrate better concurrency, but also the increased computational power of the Pentium� II processor. In this case, the degree of concurrency was much higher. Also note that the BLT compositing method causes a much larger performance degradation on the cards with high concurrency. Of course, performance will also depend upon a mixture of software (driver versions, OS version, DX version) as well as platform chipsets, and so on.

Figure 7a. Frames/sec: Pentium� processor with MMX™ technology 200MHz, 64MBytes, Matrox Mystique, Winows*95, DX5 beta 2

Figure 7b. Frames/sec: Pentium II processor, 233 MHz, 32 Mbytes, 3Dblaster*, Memphis beta 1, DX5 beta 2

Figure 7c. Frames/sec: Pentium II processor, 233 MHz, 32 Mbytes, Monster3D* (3Dfx Voodoo Graphics*), Memphis beta 1, DX5 beta 2
Since we are already rendering the scene by compositing layers, we can also consider a way to handle rendering threads at different frame rates, or even asynchronous. To perform some advanced and intensive SW rendering that will be slower than the HW scene, we can make use of image caching techniques, as in Microsoft's Talisman* initiative [see paper in 1996 SIGGraph proceedings by Shade et al entitled "Hierarchical Image Caching for Accelerated Walkthroughs of Complex Environments"] (http://www.cs.washington.edu/homes/shade/walkthru/walkthru.html)
Let's illustrate this with an example. Suppose the frame rate of the hardware-rendered portion of the scene will be around 60fps on a specific platform. Also assume that the software-rendered portion of the scene is achieving around 12fps. We have a 5:1 ratio in frame rates. Further assume that the objects rendered by the software thread do not change too much from frame to frame. We then can use the rendered scene as an image cache for the next 4 frames, with 2D-warping. The 2D warping function is much less costly than re-rendering, and is supported by some hardware. It allows the software thread to continue working on the next (5th) frame.
Figure 7 illustrates the architecture for MR2. An API currently is lacking, to control the basic process. For example, we need a controller to estimate image cache life. This lifetime is the number of frames that it can be used before re-rendering. In our example above, the life is 5. So far, we have not implemented a real MR2 example.
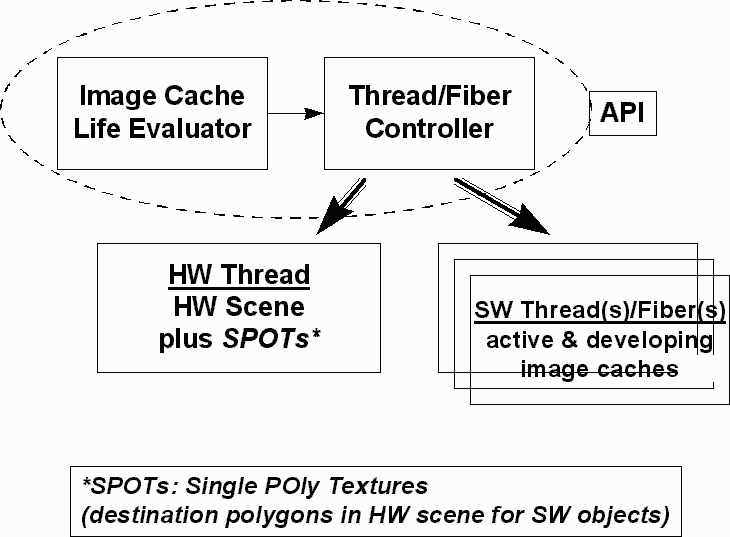
Figure 8. MR2 Architecture
The software renderings can be broken into several threads, depending upon scene complexity and requirements for each object. For example, one object may use a rendering technique much slower than that of another. These two objects can operate as independent threads. The results of all the software threads are then composited by texture mapping (with transparency) onto SPOTs.
Each software thread should make
use of a double-buffering method. The "developing
cache" is analogous to the backbuffer, the surface that the SW thread currently
rendering to. The "active cache" is the frontbuffer,
the surface that the HW thread uses as one source for compositing (warping and
texture mapping).
The idea of mixed rendering is not new. As soon as there were 3D accelerators, there were already desires to mix software and hardware pixels. We have developed a workable methodology for use with the industry-standard APIs. But issues already being addressed to improve mixed rendering are:
1. BLT with Z (not yet implemented in DirectX)
2. Better concurrency and synchronization in the API and its drivers
3. Development of "intelligent schemes" to for control (e.g. MR2)
Further developments in Mixed Rendering will provide a valuable alternative path for developers to exploit both the raw performance of 3D accelerators as well as the flexibility of software. End users will benefit from the improved quality and performance.
This section shows
some code snippets from the mixed rendering application. Full
source and precompiled executables are available from the
website.
DrawFrame is the procedure in the Main (hardware) Thread that:
1. Renders the parts of the scene done by the hardware accelerator;
2. Composites the results of the SW Thread (DrawFrameSW - see below) into this scene;
3. Flips the back and front buffers for display.
All this is done with
synchronization coordination of two events: compositeHandle &
eventHandle.
NOTE: For simplicity, this code
neglects error checking. The real code will have error checking
of course (i.e. check return values of function calls).
// Create the SW Rendering Thread and synchronization events. th = CreateThread (NULL, 0, (LPTHREAD_START_ROUTINE)DrawFrameSW, NULL, CREATE_SUSPENDED, &dwThreadId); SetThreadPriority(th, THREAD_PRIORITY_HIGHEST); eventHandle = CreateEvent(NULL, TRUE, FALSE, "SW is Ready\0"); compositeHandle = CreateEvent(NULL, TRUE, FALSE, "Composite is Done\0"); ResumeThread(th); // Start SW Thread going...
void DrawFrame(void){
// Main HW rendering and compositing loop
bResult = RenderHWScene(...); // Render HW scene (using API)
// WAIT for SW thread to be ready
WaitForSingleObject(eventHandle, DEADLOCK_TIMEOUT);
ResetEvent(eventHandle);
{ // Composite happens here... our SW rendering used a black background so we
// can use it here as a colorkey
RECT dRect, sRect;
DDSetColorKey(lpDDSurfaceSystem, RGB(0,0,0)); // Black background for colorkey
SetRect(&dRect, 200, 180, 200+255,180+255);
SetRect(&sRect, 0, 0, 255, 255);
ddrval = lpHALBuffer->Blt(&dRect, lpDDSurfaceSystem, &sRect,
DDBLT_KEYSRC | DDBLT_ASYNC, NULL); }
// Flip the HAL/FrontBuffer surface
ddrval = lpFrontBuffer->Flip(lpHALBuffer, DDFLIP_WAIT);
// Resume the SW Thread - that is, the main thread has consumed the output of the
// SW rendering. Use of double buffering would eliminate this.
SetEvent(compositeHandle);
}
void DrawFrameSW(void){
// SW rendering loop
while (TRUE) {
// Render to offscreen surface in systemmemory
bResult = RenderSWScene(...);
// SIGNAL that SW is ready
SetEvent(eventHandle);
// Suspend SW thread - until SW output is consumed into composite
WaitForSingleObject(compositeHandle,DEADLOCK_TIMEOUT);
ResetEvent(compositeHandle);
}; // loop indefinitely
}